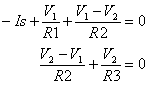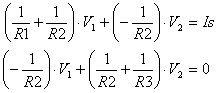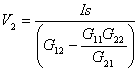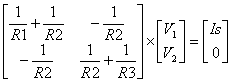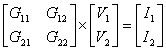Unlike other electron devices, which depend for their functioning on the flow of electric charges through a vacuum or a gas, semiconductor devices make use of the flow of current in a solid. In general, all materials may be classified in three major categories — conductors, semiconductors, and insulators — depending upon their ability to conduct an electric current. As the name indicates, a semiconductor material has poorer conductivity than a conductor, but better conductivity than an insulator.
The materials most often used in semiconductor devices are germanium and silicon. Germanium has higher electrical conductivity ( less resistance to current flow ) than silicon, and is used in most low– and medium–power diodes and transistors. Silicon is more suitable for high–power devices than germanium. One reason is that it can be used at much higher temperatures. A relatively new material which combines the principal desirable features of both germanium and silicon is gallium arsenide. When further experience with this material has been obtained, it is expected to find much wider use in semiconductor devices.Resistivity
The ability of a material to conduct current ( conductivity ) is directly proportional to the number of free ( loosely held ) electrons in the material. Good conductors, such as silver, copper, and aluminum, have large numbers of free electrons; their resistivities are of the order of a few millionths of an ohm-centimeter. Insulators such as glass, rubber, and mica, which have very few loosely held electrons, have resistivities as high as several million ohm-centimeters.
Semiconductor materials lie in the range between these two extremes, as shown in Fig. 1. Pure germanium has a resistivity of 60 ohm–centimeters. Pure silicon has a considerably higher resistivity, in the order of 60,000 obm-centimeters. As used in semiconductor devices, however, these materials contain carefully controlled amounts of certain impurities which reduce their resistivity to about 2 ohm–centimeters at room temperature ( this resistivity decreases rapidly as the temperature rises ).

Impurities
Carefully prepared semiconductor materials have a crystal structure. In this type of structure, which is called a lattice, the outer or valence electrons of individual atoms are tightly bound to the electrons of adjacent atoms in electron–pair bonds, as shown in Fig. 2. Because such a structure has no loosely held electrons, semiconductor materials are poor conductors under normal conditions. In order to separate the electron pair bonds and provide free electrons for electrical conduction, it would be necessary to apply high temperatures or strong electric fields.

When the impurity elements are added to the semiconductor material, impurity atoms take the place of semiconductor atoms in the lattice structure. If the impurity atoms added have the same number of valence electrons as the atoms of the original semiconductor material, they fit neatly into the lattice, forming the required number of electron–pair bonds with semiconductor atoms. In this case, the electrical properties of the material are essentially unchanged.
When the impurity atom has one more valence electron than the semiconductor atom, however, this extra electron cannot form an electron pair bond because no adjacent valence electron is available. The excess electron is then held very loosely by the atom, as shown in Fig. 3, and requires only slight excitation to break away. Consequently, the presence of such excess electrons makes the material a better conductor, i.e., its resistance to current flow is reduced.

A different effect is produced when an impurity atom having one less valence electron than the semiconductor atom is substituted in the lattice structure. Although all the valence electrons of the impurity atom form electron–pair bonds with electrons of neighboring semiconductor atoms, one of the bonds in the lattice structure cannot be completed because the impurity atom lacks the final valence electron. As a result, a vacancy or "hole" exists in the lattice, as shown in Fig. 4. An electron from an adjacent electron–pair bond may then absorb enough energy to break its bond and move through the lattice to fill the hole. As in the case of excess electrons, the presence of "holes" encourages the flow of electrons in the semiconductor material; consequently, the conductivity is increased and the resistivity is reduced.

P–N JUNCTIONS
When n–type and p–type materials are joined together, as shown in Fig. 5, an unusual but very important phenomenon occurs at the interface where the two materials meet ( called "the p-n junction" ). An interaction takes place between the two types of material at the junction as a result of the holes in one material and the excess electrons in the other.

Thermal energy causes charge carriers ( electrons and holes ) to diffuse from one side of the p–n junction to the other side; this flow of charge carriers is called diffusion current. As a result of the diffusion process, however, a potential gradient builds up across the space–charge region. This potential gradient can be represented, as shown in Fig. 6, by an imaginary battery connected across the p–n junction. ( The battery symbol is used merely to illustrate internal effects; the potential it represents is not directly measurable. )

CURRENT FLOW
When an external battery is connected across a p–n junction, the amount of current flow is determined by the polarity of the applied voltage and its effect on the space–charge region. In. Fig. 7a, the positive terminal of the battery is connected to the n–type material and the negative terminal to the p–type material.

In Fig. 7b, the positive terminal of the external battery is connected to the p–type material and the negative terminal to the n–type material.

The generalized voltage–current characteristic for a p–n junction in Fig. 8 shows both the reverse–bias and forward–bias regions.

N–P–N and P–N–P STRUCTURES
fig.7 shows that a p–n junction biased in the reverse direction is equivalent to a high–resistance element ( low current for a given applied voltage ), while a junction biased in the forward direction is equivalent to a low–resistance element ( high current for a given applied voltage ). Because the power developed by a given current is greater in a high–resistance element than in a low–resistance element ( P=I2R ), power gain can be obtained in a structure containing two such resistance elements if the current flow is not materially reduced. A device containing two p–n junctions biased in opposite directions can operate in this fashion.
Such a two–junction device is shown in Fig. 9.